



{kind=link}
{kind=link}
0x00 前言
在今年6月的Unite Europe 2017大会上 Unity 的CTO Joachim Ante演示了未来Unity新的编程特性——C# Job系统,它提供了编写多线程代码的一种既简单又安全的方法。Joachim通过一个大规模群落行为仿真的演示,向我们展现了最新的Job系统是如何充分利用CPU多核架构的优势来提升性能的。
但是吸引我的并非是C# Job如何利用多线程实现性能的提升,相反,吸引我的是如何在现在还没有C# Job系统的Unity中实现类似的效果。
在Ante的session中,他的演示主要是利用多核CPU提高计算效率来实现大群体行为。那么我就来演示一下,如何利用GPU来实现类似的目标吧。利用GPU做一些非渲染的计算也被称为GPGPU——General-purpose computing on graphics processing units,图形处理器通用计算。
0x01 CPU的限制
为何Joachim 要用这种大规模群落行为的仿真来宣传Unity的新系统呢?
其实相对来说复杂的并非逻辑,这里的关键词是“大规模”——在他的演示中,实现了20,000个boid的群体效果,而更牛逼的是帧率保持在了40fps上下。
事实上自然界中的这种群体行为并不罕见,例如大规模的鸟群,大规模的鱼群。 在搜集资料的时候,我还发现了一位优秀的水下摄影师、加利福尼亚海湾海洋计划总监octavio aburto的个人网站上的一些让人惊叹的作品。
在搜集资料的时候,我还发现了一位优秀的水下摄影师、加利福尼亚海湾海洋计划总监octavio aburto的个人网站上的一些让人惊叹的作品。 图片来自Octavio Aburto
图片来自Octavio Aburto 图片来自Octavio Aburto
图片来自Octavio Aburto
而要在计算机上模拟出这种自然界的现象,乍看上去似乎十分复杂,但实际上却并非如此。
查阅资料,可以发现早在1986年就由Craig Reynolds提出了一个逻辑简单,而效果很赞的群体仿真模型——而作为这个群体内的个体的专有名词boid(bird-oid object,类鸟物)也是他提出的。
简单来说,一个群体内的个体包括3种基本的行为:
- Separation:顾名思义,该个体用来规避周围个体的行为。
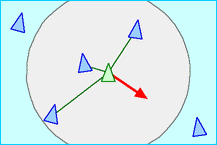
- Alignment:作为一个群体,要有一个大致统一的前进方向。因此作为群体中的某个个体,可以根据自己周围的同伴的前进方向获取一个前进方向。
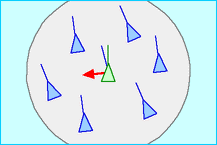
- Cohesion:同样,作为一个群体肯定要有一个向心力。否则队伍四散奔走就不好玩了,因此每个个体就可以根据自己周围同伴的位置信息获取一个向中心聚拢的方向。
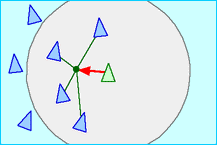
以上三种行为需要同时加以考虑,才有可能模拟出一个接近真实的效果。
Vector3 direction = separation+ alignment + (cohesion - boid.position).normalized;可以看出,这里的逻辑并不复杂,但是麻烦的问题在于实现这套逻辑的前提是每个个体boid都需要获取自己周围的同伴信息。
因此最简单也最通用的方式就是每个boid都要和群落中的所有boid比较位置信息,获取二者之间的距离,如果小于阈值则判定是自己周围的同伴。而这种比较的时间复杂度显然是O(n2)。因此,当群体是由几百个个体组成时,直接在cpu上计算时的表现还是可以接受的。但是数量一旦继续上升,效果就很难保证了。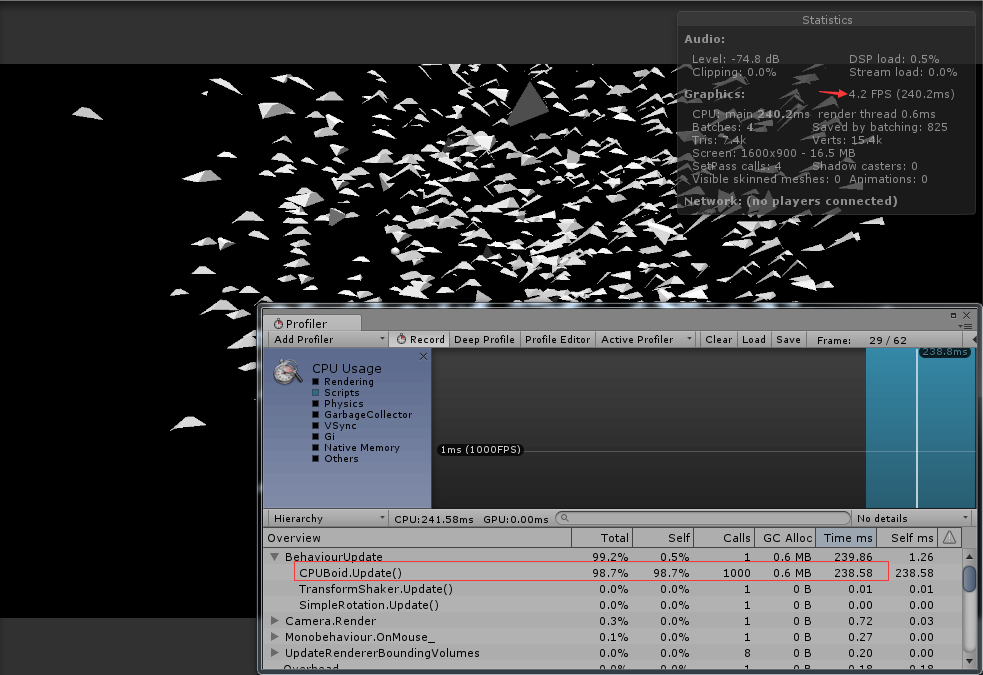
当然,在Unity中我们还可以利用它的物理组件来获取一个boid个体周围的同伴信息:
Physics.OverlapSphere(Vector3 position, float radius, int layerMask);这个方法会返回和自己重叠的对象列表,由于unity使用了空间划分的机制,所以这种方式的性能要好于直接比较n个boid之间的距离。
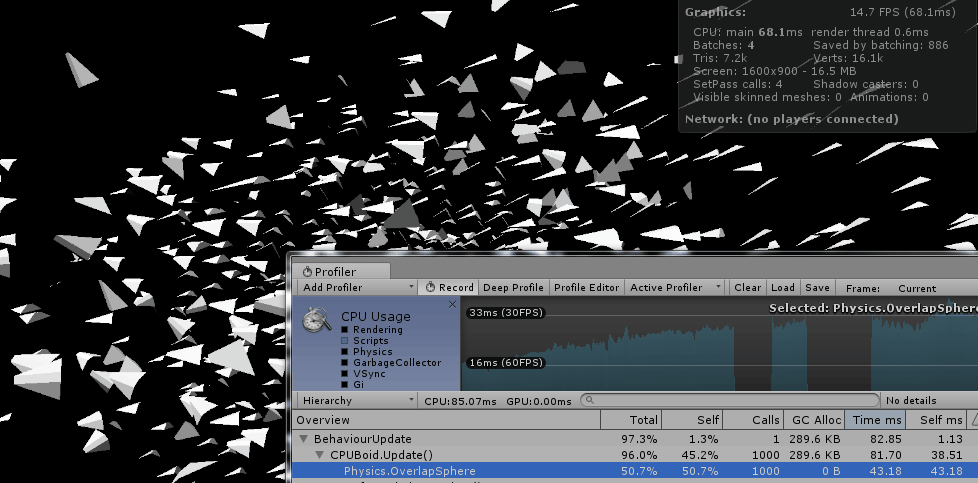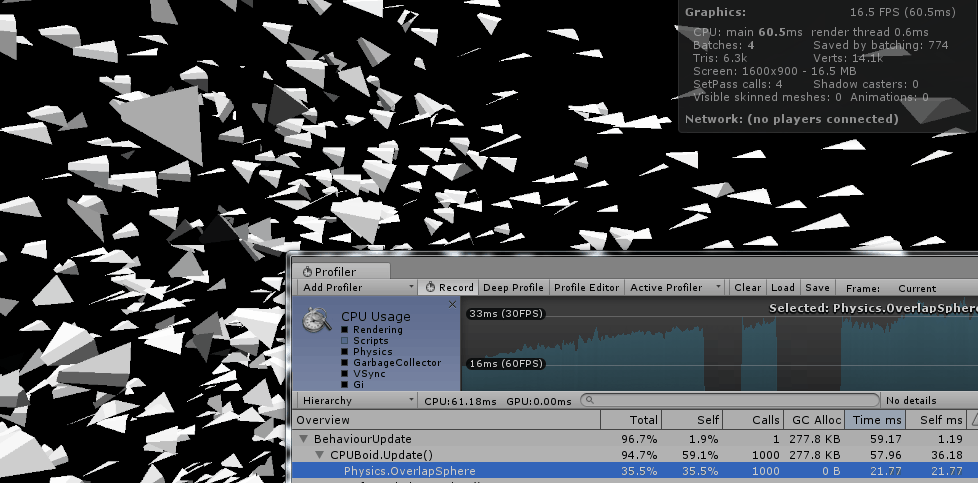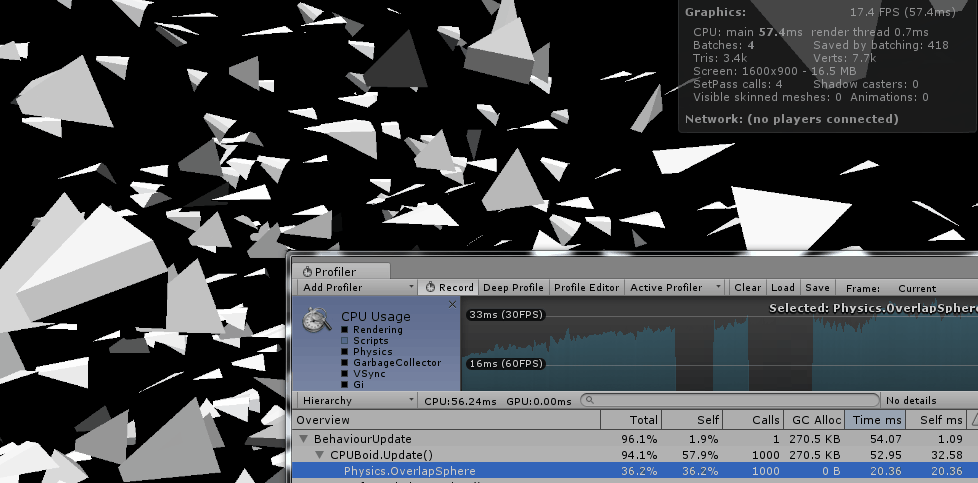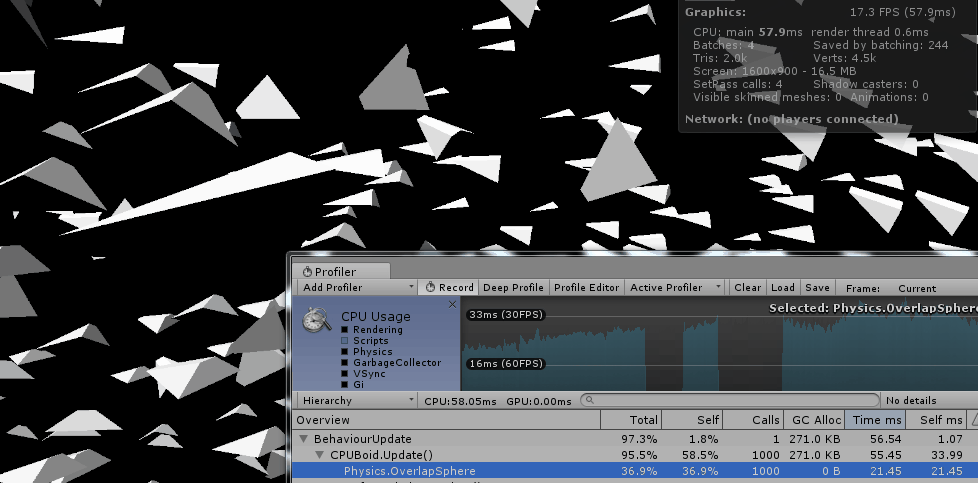
但是即便如此,cpu的计算能力仍然是一个瓶颈。随着群体个体数量的上升,性能也会快速的下降。
0x02 GPU的优势
既然限制的瓶颈在于CPU面对大规模个体时的计算能力的不足,那么一个自然的想法就是将这部分计算转移到更擅长大规模计算的GPU上来进行。
CPU的结构复杂,主要完成逻辑控制和缓存功能,运算单元较少。与CPU相比,GPU的设计目的是尽可能的快速完成图像处理,通过简化逻辑控制并增加运算单元实现了高性能的并行计算。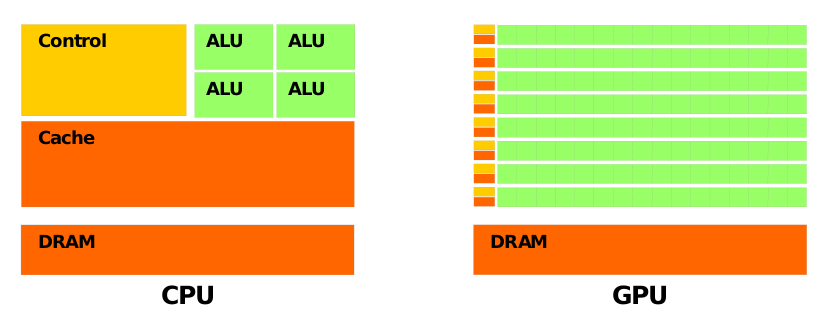 利用GPU的超强计算能力来实现一些渲染之外的功能并非一个新的概念,早在十年前nvidia就为GPU引入了一个易用的编程接口,即CUDA统一计算架构,之后微软推出了DirectCompute——它随DirectX 11一同发布。
利用GPU的超强计算能力来实现一些渲染之外的功能并非一个新的概念,早在十年前nvidia就为GPU引入了一个易用的编程接口,即CUDA统一计算架构,之后微软推出了DirectCompute——它随DirectX 11一同发布。
和常见的vertex shader和fragment shader类似,要在GPU运行我们自己设定的逻辑也需要通过shader,不过和传统的shader的不同之处在于,compute shader并非传统的渲染流水线中的一个阶段,相反它主要用来计算原本由CPU处理的通用计算任务,这些通用计算常常与图形处理没有任何关系,因此这种方式也被称为GPGPU——General-purpose computing on graphics processing units,图形处理器通用计算。
利用这些功能,之前由CPU来实现的计算就可以转移到计算能力更强大的GPU上来进行了,比如物理计算、AI等等。
而Unity的Compute Shader十分接近DirectCompute,最初Unity引入Compute Shader时仅仅支持DirectX 11,不过目前的版本已经支持别的图形API了。详情可以参考:Unity - Manual: Compute shaders。
在Unity中我们可以很方便的创建一个Compute Shader,一个Unity创建的默认Compute Shader如下所示:
// Each #kernel tells which function to compile; you can have many kernels
#pragma kernel CSMain
// Create a RenderTexture with enableRandomWrite flag and set it
// with cs.SetTexture
RWTexture2D<float4> Result;
[numthreads(8,8,1)]
void CSMain (uint3 id : SV_DispatchThreadID)
{
// TODO: insert actual code here!
Result[id.xy] = float4(id.x & id.y, (id.x & 15)/15.0, (id.y & 15)/15.0, 0.0);
}这里我先简单的介绍一下这个Compute Shader中的相关概念,首先在这里我们指明了这个shader的入口函数。
#pragma kernel CSMain之后,声明了在compute shader中操作的数据。
RWTexture2D<float4> Result;这里使用的是RWTexture2D,而我们更常用的是RWStructuredBuffer(RW在这里表示可读写)。
之后是很关键的一行:
[numthreads(8,8,1)]这里首先要说一下Compute Shader执行的线程模型。DirectCompute将并行计算的问题分解成了多个线程组,每个线程组内又包含了多个线程。
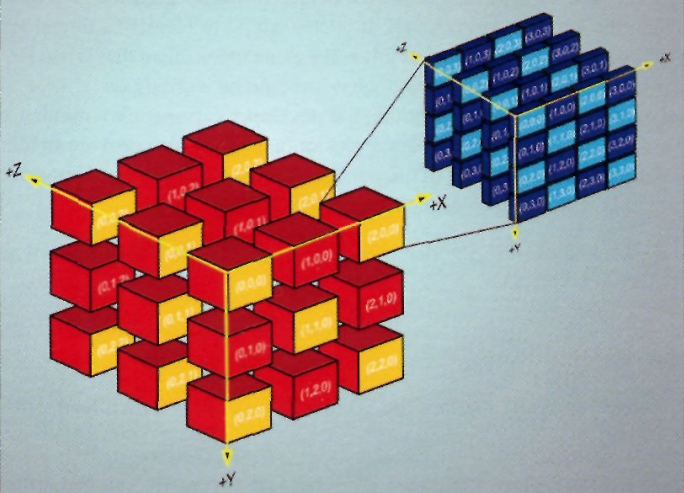
[numthreads(8,8,1)]的意思是在这个线程组中分配了8x8x1=64个线程,当然我们也可以直接使用
[numthreads(64,1,1)]因为三维线程模型主要是为了方便某些使用情景,和性能关系不大,硬件在执行时仍然是把所有线程当做一维的。
至此,我们已经在shader中确定了每个线程组内包括几个线程,但是我们还没有分配线程组,也没有开始执行这个shader。
和一般的shader不同,compute shader和图形无关,因此在使用compute shader时不会涉及到mesh、material这些内容。相反,compute shader的设置和执行要在c#脚本中进行。
this.kernelHandle = cshader.FindKernel("CSMain");
......
cshader.SetBuffer(this.kernelHandle, "boidBuffer", buffer);
......
cshader.Dispatch(this.kernelHandle, this.boidsCount, 1, 1);
buffer.GetData(this.boidsData);
......在c#脚本中准备、传送数据,分配线程组并执行compute shader,最后数据再从GPU传递回CPU。
不过,这里有一个问题需要说明。虽然现在将计算转移到GPU后计算能力已经不再是瓶颈,但是数据的转移此时变成了首要的限制因素。而且在Dispatch之后直接调用GetData可能会造成CPU的阻塞。因为CPU此时需要等待GPU计算完毕并将数据传递回CPU,所以希望日后Unity能够提供一个异步版本的GetData。
最后将行为模拟的逻辑从CPU转移到GPU之后,模拟10,000个boid组成的大群组在我的笔记本上已经能跑在30FPS上下了。

完整的项目可以到这里到这里下载:
chenjd/Unity-Boids-Behavior-on-GPGPU
ref:
【1】wikipedia-Boids
【2】Craig Reynolds
【3】Compute Shader Overview
【4】Compute shaders
各位如果觉得有趣的话,欢迎点个赞。
-EOF-
最后打个广告,欢迎支持我的书《Unity 3D脚本编程》

欢迎大家关注我的公众号慕容的游戏编程:chenjd01

这样的操作会不会对A卡有兼容性问题呢?